
ローカルLLMって何だろう?
ChatGPTやClaudeといったAIが話題ですが、これらはすべてクラウド上のサーバーで動いているため、使うたびにインターネット経由でデータをやり取りしています。一方、「ローカルLLM」とは自分のPCの中でLLMを動かす技術のことです。
LLMとは何か
LLM(Large Language Model:大規模言語モデル)とは、膨大なテキストデータを学習することで、自然な文章を生成できるようになったAIモデルのことです。GPT-4やClaudeなどが代表例で、以下のような仕組みで動いています。
- 📚 事前学習:インターネット上の大量のテキスト(ウェブ記事・書籍・コードなど)から言語のパターンを学習
- 🧠 Transformer構造:入力テキストの「どの単語が重要か」を計算する注意機構(アテンション)を持つニューラルネットワーク
- 💬 推論:入力文章の続きに来る単語を確率的に予測し、自然な回答を生成
主なLLMの種類
| モデル名 | 開発元 | 特徴 | ローカル実行 |
|---|---|---|---|
| GPT-4o | OpenAI | 高い汎用性・多言語対応 | ❌ クラウドのみ |
| Claude 3.5 | Anthropic | 長文処理・コード生成が得意 | ❌ クラウドのみ |
| Gemini | マルチモーダル・Google連携 | ❌ クラウドのみ | |
| Llama 3.2 | Meta | オープンソース・商用利用可 | ✅ ローカル実行可能 |
| Mistral | Mistral AI | 軽量で高速・欧州産 | ✅ ローカル実行可能 |
| Gemma 3 | 軽量版・研究・個人用途向け | ✅ ローカル実行可能 |
GPT-4oやClaudeはクラウドAPIでのみ提供されていますが、MetaのLlama・MistralなどはオープンソースとしてリリースされているためPC上でも動かせます。今回使うllama3.2:3bは、3.2B(32億)パラメータの比較的コンパクトなモデルです。
クラウドLLMとローカルLLMの違い
| クラウドLLM | ローカルLLM | |
|---|---|---|
| 実行場所 | 企業サーバー(インターネット経由) | 自分のPC |
| 性能 | 最高水準(GPT-4o等) | PC性能に依存(小〜中規模モデル) |
| コスト | API使用料(従量課金) | 電気代のみ(基本無料) |
| プライバシー | データが外部に送信される | 完全にローカル完結 |
| オフライン | 不可 | 可能 |
ローカルLLMのメリット・デメリット
✅ メリット
- 🔒 プライバシー完全保護:入力した内容が外部に送信されない。社内の機密情報や個人情報を扱う場面でも安心して使える
- 💰 コストゼロ:一度モデルをダウンロードすれば、電気代以外のコストがかからない。GPT-4のAPI代が気になる方には特に嬉しい
- 📡 オフライン動作:インターネット接続がなくても使える。出張先・飛行機の中でも利用可能
- ⚡ レイテンシがない:サーバーとの通信遅延がなく、ローカルのハードウェア速度がそのまま応答速度になる
- 🛠️ カスタマイズ自由:モデルのパラメータやシステムプロンプトを自由に調整できる(後述)
❌ デメリット
- 🧠 性能がクラウドに劣る:PCで動かせるモデルはパラメータ数が少なく、GPT-4oやClaudeと比べると回答精度が落ちる。特に高度な推論や日本語の精度は差が大きい
- 💾 ストレージが必要:モデルサイズは2GB〜数十GBに及ぶ。ディスク容量に余裕が必要
- 🖥️ 高性能PCが必要:快適に動かすにはある程度のメモリ・GPU性能が求められる(ただしApple Siliconは驚くほど快適)
- 🌐 最新情報に弱い:学習データのカットオフ以降の情報を知らない。インターネット検索との連携も自前で実装が必要
私の使い分けとしては、「試してみたいアイデアの壁打ち・プライベートなコードレビュー・オフライン環境」にはローカルLLM、「精度が必要な作業・最新情報を参照したい場面」にはクラウドLLMという感じでうまく併用するのがよさそうだと感じました。
Ollamaとは?
Ollama(オラマ)は、ローカルLLMを簡単に動かすためのツールです。通常、LLMをローカルで実行するにはPyTorchのセットアップやGPUドライバの設定など、かなりの手間が必要です。Ollamaはそのあたりを全部まとめて面倒を見てくれる「LLMのパッケージマネージャー」のような存在です。
- ✅
brew install ollamaの一発インストール - ✅
ollama pull <モデル名>でモデルをダウンロード - ✅
ollama run <モデル名>でチャット開始 - ✅ REST API(localhost:11434)でプログラムから呼び出しも可能
- ✅ Apple Silicon(M1/M2/M3/M4)に最適化済み
公式サイト:https://ollama.com/
利用可能なモデル一覧:https://ollama.com/library
MacへのOllamaインストール手順
ここからは実際にMacへインストールした手順を紹介します。今回使ったのはApple M4チップのMacです。
Homebrewを使ってインストールします。Homebrewが入っていない方は先に公式サイトからインストールしてください。
brew install ollama
Homebrewで一発インストール。時間はかかりますが操作は一行で完了します。
インストールが完了したら、Ollamaのバックグラウンドサービスを起動します。
brew services start ollama
# または一時的に起動する場合:
ollama serveバージョン確認もしてみましょう。
ollama --version
# → ollama version is 0.6.8モデルをダウンロードして動かしてみた
Ollamaではollama pullコマンドでモデルをダウンロードします。今回は軽量で日本語もある程度対応しているllama3.2:3b(約2.0GB)を試しました。
ollama pull llama3.2:3b
ダウンロード中は進捗バーが表示されます。2GBなので数分で完了しました。
ダウンロード済みのモデルはollama listで確認できます。
ollama list
NAME・ID・SIZE・MODIFIEDが表示されます。llama3.2:3bは2.0GBと確認できました。
それでは実際にチャットしてみます。
ollama run llama3.2:3b
ターミナル上でチャット形式の対話が始まります。日本語も問題なく応答してくれました。
3Bパラメータと小さめのモデルにもかかわらず、日本語で自然なやり取りができて少し驚きました。複雑な推論や高度な質問には限界がありますが、ちょっとした壁打ちや下書き作成には十分使えそうです。チャット終了は /bye と入力します。
Apple Siliconの速度に驚いた
ローカルLLMといえば「遅い」というイメージがありましたが、Apple Silicon(今回はM4)では予想以上に快適でした。
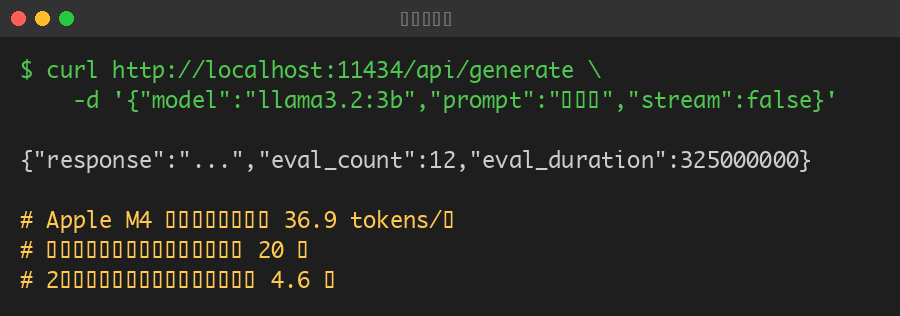
計測した結果、約36.9トークン/秒でした。これは1秒間に30〜40文字程度が出力されるイメージです。
Apple SiliconのMac(M1〜M4)はCPUとGPUがメモリを共有するユニファイドメモリアーキテクチャを採用しており、これがローカルLLMの実行に非常に相性が良いです。NVIDIAのGPUがなくてもこれだけ速く動くのは正直驚きでした。
参考:Apple シリコンのメモリアーキテクチャ(Apple Developer)
ハマったポイント:エラーの原因と対処
試している中で一度エラーに遭遇しました。実際のエラー画面がこちらです。
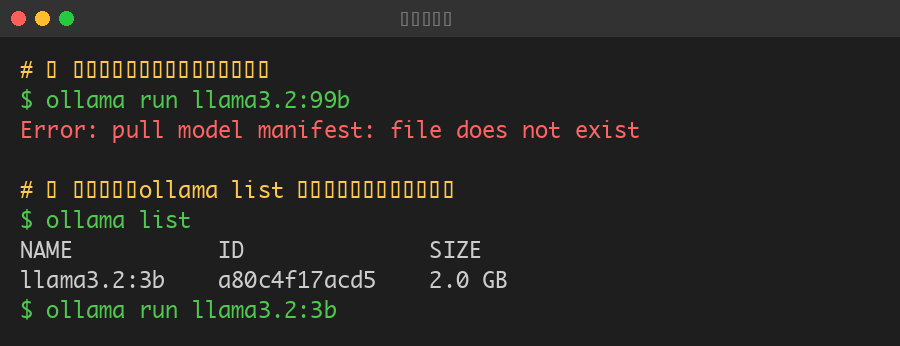
モデル名を間違えるとこのようなエラーが表示されます。
このエラーは存在しないモデル名や誤ったタグを指定したときに発生します。対処法は以下の通りです。
- ✅ https://ollama.com/library で正確なモデル名を確認する
- ✅
ollama listでダウンロード済みモデルを確認する - ✅ タグ(
llama3.2:3bの:3b部分)を省略すると最新版が使われる
Ollamaのサービスが起動していない場合は brew services start ollama か ollama serve で起動するのも忘れずに。
カスタマイズできるパラメータを試してみた
Ollamaはコマンド実行やAPIリクエスト時にさまざまなパラメータを指定して動作を調整できます。以下のようにREST API経由でパラメータを渡す方法が最も柔軟です。
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2:3b",
"prompt": "AIとは何ですか?",
"stream": false,
"options": {
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40,
"repeat_penalty": 1.1,
"num_predict": 200
}
}'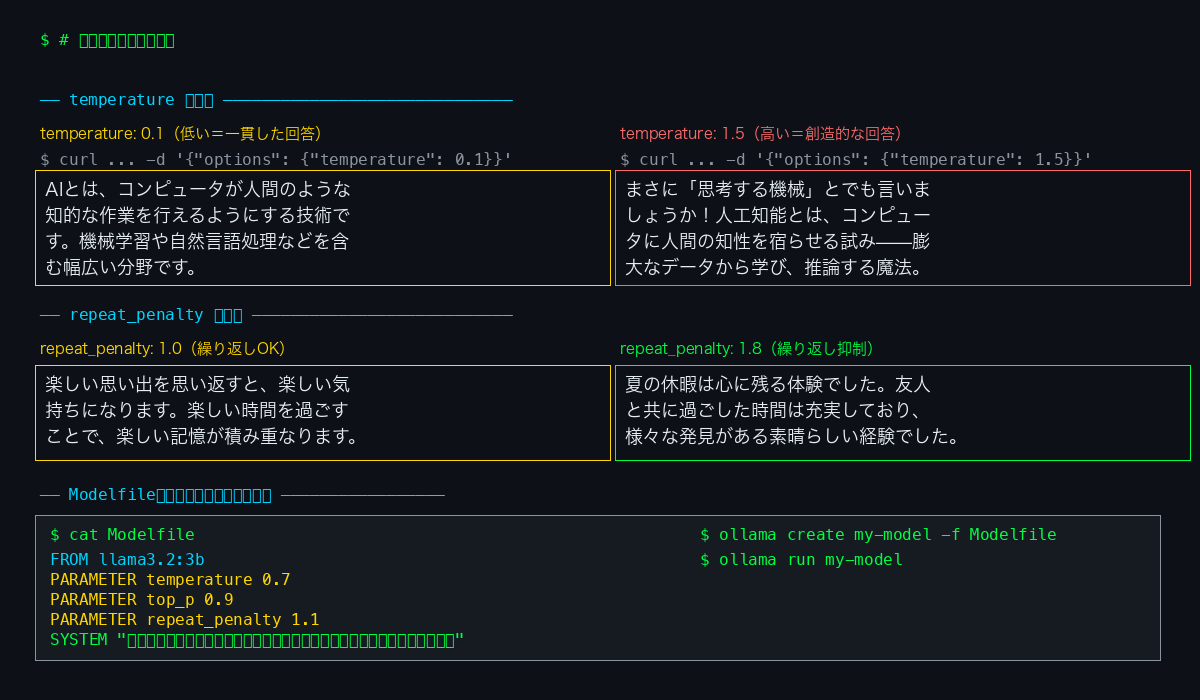
temperatureとrepeat_penaltyを変えた場合の出力の違いを実際に比較しました。
主なパラメータ一覧
| パラメータ | 範囲 | デフォルト | 効果 |
|---|---|---|---|
temperature |
0.0〜2.0 | 0.8 | 低い=一貫した回答、高い=創造的・多様な回答 |
top_p |
0.0〜1.0 | 0.9 | 確率上位p%のトークンから選択。低いほど保守的 |
top_k |
整数 | 40 | 確率上位k個から選択。0で無効化 |
repeat_penalty |
1.0〜2.0 | 1.1 | 高いほど同じ表現の繰り返しを避けるようになる |
num_predict |
整数 | -1(無制限) | 生成するトークン数の上限 |
num_ctx |
整数 | モデル依存 | コンテキストウィンドウサイズ(llama3.2の最大:131,072) |
実際に試して感じたこと
- temperature 0.1:毎回ほぼ同じ回答が返ってくる。事実確認や要約に向いている
- temperature 1.5:表現が豊かになるが、ときどき的外れな回答も。文章のアイデア出しに
- repeat_penalty 1.8:同じ言い回しをしなくなるが、不自然さが増す場合も
Modelfile:設定を永続化する
パラメータ設定やシステムプロンプト(キャラクター設定)を固定したいときはModelfileを使います。
# Modelfileを作成
FROM llama3.2:3b
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER repeat_penalty 1.1
PARAMETER num_predict 200
SYSTEM """
あなたは親切な技術者アシスタントです。
専門用語には必ず説明を加え、初心者にも分かりやすく答えます。
"""# カスタムモデルを作成して実行
ollama create my-assistant -f Modelfile
ollama run my-assistantModelfileを使えばollama runのたびに同じ設定が適用されるので、用途別のモデルを複数作っておくと便利です。
公式ドキュメント:Ollama Modelfile ドキュメント
まとめ
OllamaをMacに入れてローカルLLMを動かしてみた感想をまとめます。
- ✅ インストールが超簡単:Homebrewの一行で完了
- ✅ Apple M4では思った以上に速い:36.9トークン/秒は会話に十分
- ✅ プライバシー面で安心:ローカル完結なのでどんな内容でも試せる
- ✅ REST APIで自作アプリに組み込める:localhost:11434を叩くだけ
- ⚠️ 高精度作業はクラウドLLMに軍配:GPT-4oやClaudeとは性能差あり
- ⚠️ 日本語精度はモデルによって差がある:用途に合わせてモデル選択を
個人的には「クラウドLLMを使うほどでもないアイデアのメモ書き確認」「社外に出せないコードのレビュー」「API料金を気にせずたくさん試したいとき」などにローカルLLMを活用していこうと思っています😊
気になった方はぜひOllama公式サイトからお試しを!モデルはライブラリページから自分の用途に合ったものを選んでみてください。
それでは、今回はここまで。ありがとうございました😊