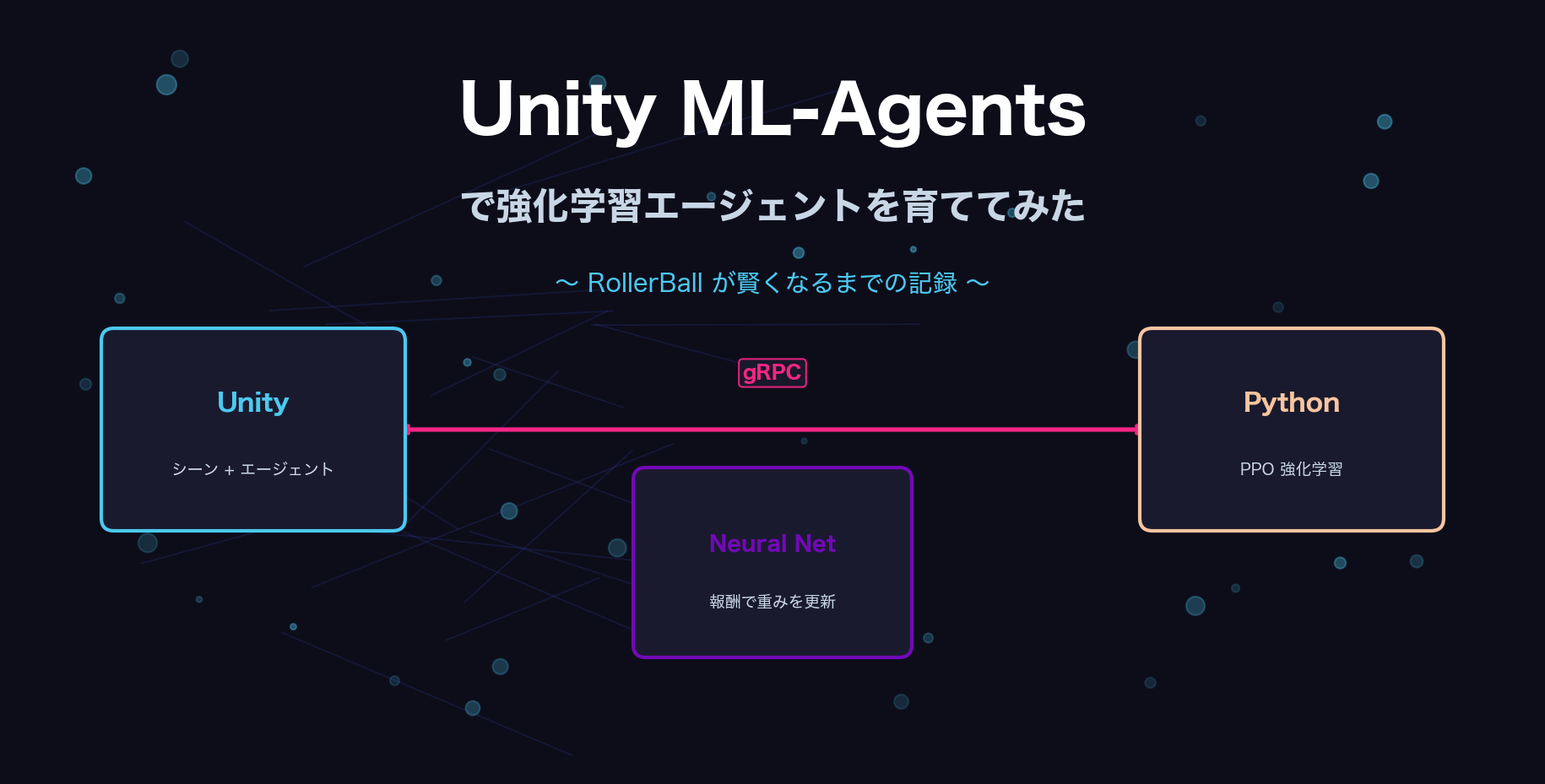
「AIにゲームキャラを自分で学習させたい」——そう思ってUnityのML-Agentsを試してみました。想像以上に深くて、環境構築だけで半日かかりましたが、エージェントが少しずつ「賢く」なっていく様子は本当に面白かったです。今回はその一部始終をご紹介します。
強化学習とML-Agentsって何だろう?
まず基本から。強化学習(Reinforcement Learning)とは、AIが「試行錯誤」を繰り返しながら自分で最適な行動を学ぶ仕組みです。
- 観測(Observation):AIが「見える」情報(自分の位置、目標の位置、速度など)
- 行動(Action):AIが取る動作(どっちに力を加えるか)
- 報酬(Reward):行動の良し悪しを数値で教える(ゴールに到達したら+1、落ちたら−1)
人間が「正解のやり方」を教えるのではなく、報酬という「評価」を与えることで、AIが自分で最適解を探し出すのが強化学習の肝です。
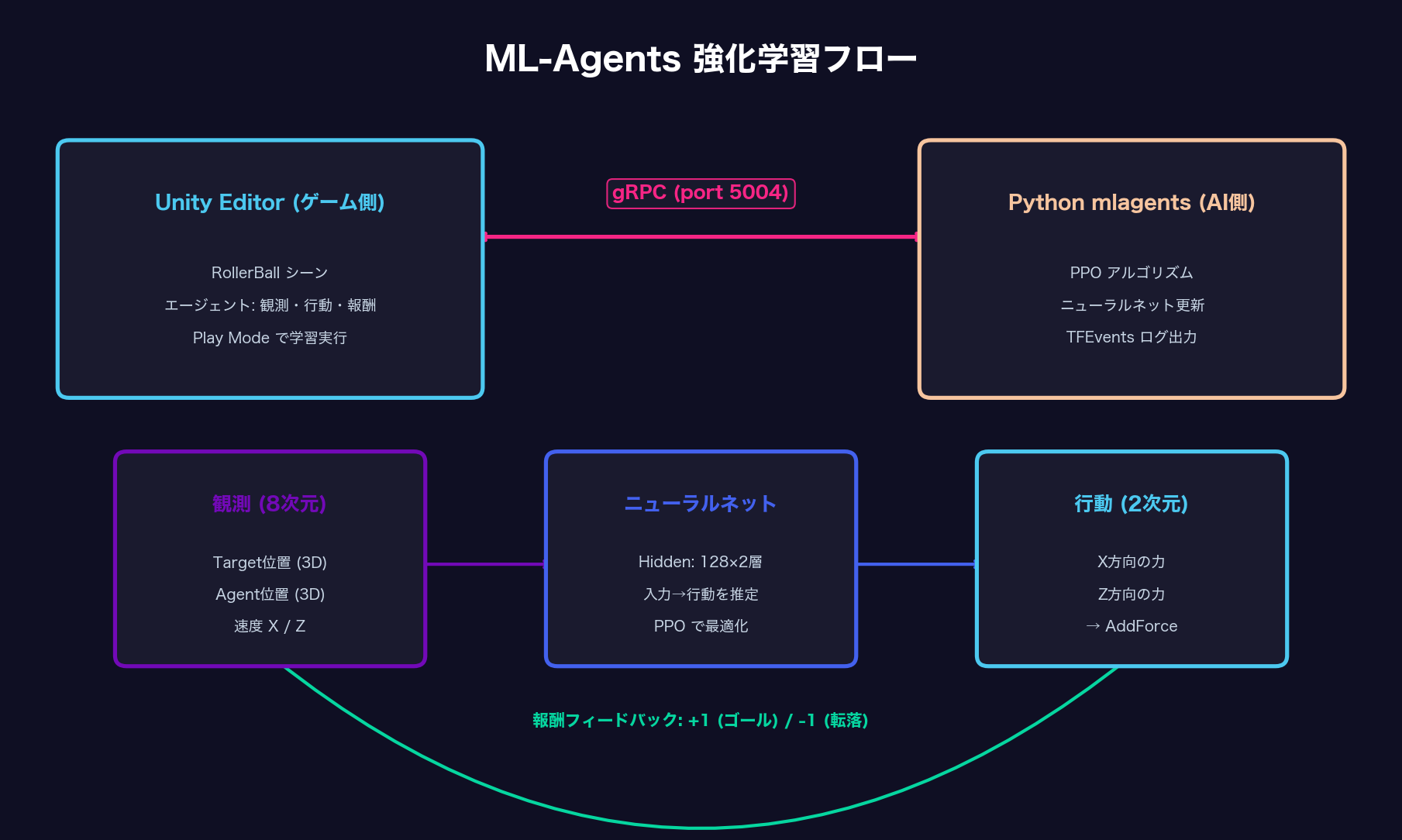
Unity ML-AgentsはUnity向けの強化学習フレームワークで、UnityのゲームエンジンをAIの「学習環境」として使えます。Unityがシミュレーション環境を担当し、PythonのAIライブラリ(PyTorch)が学習アルゴリズムを担当、両者がgRPCで通信する仕組みです。
環境セットアップが意外とハードだった
ML-Agentsのセットアップは、一筋縄ではいきませんでした。特にmacOS(Apple Silicon)での依存関係の解決に苦労しました。
前提:バージョン制約が厳しい
mlagents 1.1.0(最新版)を動かすにはPython 3.10.12以下が必要です。標準的なmacOSに入っているPython 3.12や3.11では動きません。pyenvでPython 3.10.12を別途インストールする必要があります。
# pyenvでPython 3.10.12をインストール
CFLAGS="-I$(brew --prefix xz)/include" \
LDFLAGS="-L$(brew --prefix xz)/lib" \
pyenv install 3.10.12
# 仮想環境を作成
python3.10 -m venv ~/devel/unity/ml_agents_env
source ~/devel/unity/ml_agents_env/bin/activateハマりポイント①:grpcioのビルドエラー
mlagentsをそのままpip installすると、grpcioのソースビルドが始まり、pkg_resourcesが見つからないとエラーになります。解決策は--prefer-binaryフラグです。
# grpcioはバイナリホイールを強制指定
pip install "grpcio>=1.11.0,<1.49.0" --prefer-binaryハマりポイント②:protobufバージョン競合
mlagentsはprotobuf 3.x系が必要ですが、デフォルトでは最新版(7.x)が入ってしまいます。
pip install "protobuf<3.21" --prefer-binaryハマりポイント③:mlagents自体は--no-depsで
mlagentsの依存関係解決が荒れるため、本体は--no-depsでインストールし、依存パッケージを個別に入れるのが最も安定します。
pip install mlagents==1.1.0 --no-deps
pip install mlagents-envs==1.1.0 --no-deps --prefer-binary
pip install torch torchvision cloudpickle gym --prefer-binaryUnityパッケージ側の注意点
Unity 6(6000.0系)を使う場合、com.unity.ml-agentsの4.0.3以降が必要です。manifest.jsonに直接記述します。
{
"dependencies": {
"com.unity.ml-agents": "4.0.3",
...
}
}RollerBallシーンを作る
今回作ったのはRollerBall——白い球(エージェント)が赤い球(ターゲット)を目指して転がるシンプルなシーンです。強化学習の教科書的なサンプルです。
シーン構成
- Floor:Plane(Scale 10, 1, 10)——落ちると失敗の床
- Target:球体(赤)——エピソードごとにランダム位置に配置
- RollerAgent:球体(白)——学習するエージェント本体
RollerAgentには以下のコンポーネントを追加します:
Rigidbody——物理演算用RollerAgent.cs——独自スクリプト(後述)Behavior Parameters——ML-Agentsの設定(観測数・行動数など)Decision Requester——何ステップごとにAIに判断させるか
Behavior Parametersの設定値:
- Behavior Name:
RollerBall - Vector Observation Space Size:
8 - Continuous Actions:
2
エージェントのC#スクリプト解説
AIの「目」「手」「評価」を定義するのがこのスクリプトです。Agentクラスを継承して4つのメソッドをオーバーライドします。
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
public class RollerAgent : Agent
{
public Transform target;
public float speed = 10f;
private Rigidbody rb;
// 初期化:Rigidbodyを取得
public override void Initialize()
{
rb = GetComponent<Rigidbody>();
}
// エピソード開始時:Targetをランダム位置に、自分は中央に戻す
public override void OnEpisodeBegin()
{
if (transform.localPosition.y < 0)
{
rb.angularVelocity = Vector3.zero;
rb.linearVelocity = Vector3.zero;
transform.localPosition = new Vector3(0, 0.5f, 0);
}
target.localPosition = new Vector3(
Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
// 観測収集:AIが「見る」情報を8次元で渡す
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(target.localPosition); // 3次元
sensor.AddObservation(transform.localPosition); // 3次元
sensor.AddObservation(rb.linearVelocity.x); // 1次元
sensor.AddObservation(rb.linearVelocity.z); // 1次元
}
// 行動受け取り&報酬付与:AIの判断を受けて物理演算、評価する
public override void OnActionReceived(ActionBuffers actions)
{
Vector3 controlSignal = Vector3.zero;
controlSignal.x = actions.ContinuousActions[0];
controlSignal.z = actions.ContinuousActions[1];
rb.AddForce(controlSignal * speed);
float distToTarget = Vector3.Distance(
transform.localPosition, target.localPosition);
if (distToTarget < 1.42f)
{
SetReward(1.0f); // ゴール到達! +1
EndEpisode();
}
if (transform.localPosition.y < 0)
{
SetReward(-1.0f); // 転落… -1
EndEpisode();
}
}
}ポイントは報酬設計です。この例では「ゴールに着いたら+1、落ちたら−1」というシンプルな報酬のみですが、これだけでAIは「転ばずにゴールを目指す」という戦略を自力で発見します。
PPO設定ファイルの中身
Pythonの学習アルゴリズムの設定は.yamlファイルで行います。今回使ったのはPPO(Proximal Policy Optimization)というアルゴリズムで、現在の強化学習では最もよく使われる手法のひとつです。
behaviors:
RollerBall:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 500000
time_horizon: 64
summary_freq: 10000主なパラメータの意味:
batch_size / buffer_size:一度に学習するデータ量。小さいほど更新が頻繁になるlearning_rate:学習率。大きすぎると発散、小さすぎると収束が遅いhidden_units / num_layers:ニューラルネットの規模(128ユニット×2層)gamma:将来の報酬をどれだけ重視するか(0.99 = かなり先まで考慮)max_steps:最大学習ステップ数(500,000ステップで学習終了)
学習の実行コマンド
source ~/devel/unity/ml_agents_env/bin/activate
cd ~/devel/unity/MLAgents_RollerBall
mlagents-learn config/rollerball.yaml --run-id=RollerBall_01このコマンドを実行するとPython側が待機状態になり、UnityエディタでPlayボタンを押すと通信が確立して学習がスタートします。コンソールにRegistered Communicator in Agent.と表示されれば成功です。
実際に学習させてみた結果
実際にUnity EditorをPlay Modeにして学習を開始しました。Pythonターミナルには10,000ステップごとにログが流れ、Unityの画面ではボールが動き回るのが見えます。
学習が進むにつれて、エージェントの挙動が変化していくのが興味深かったです。最初はランダムに動き回り、たまたまゴールに当たる→転落する、を繰り返していました。
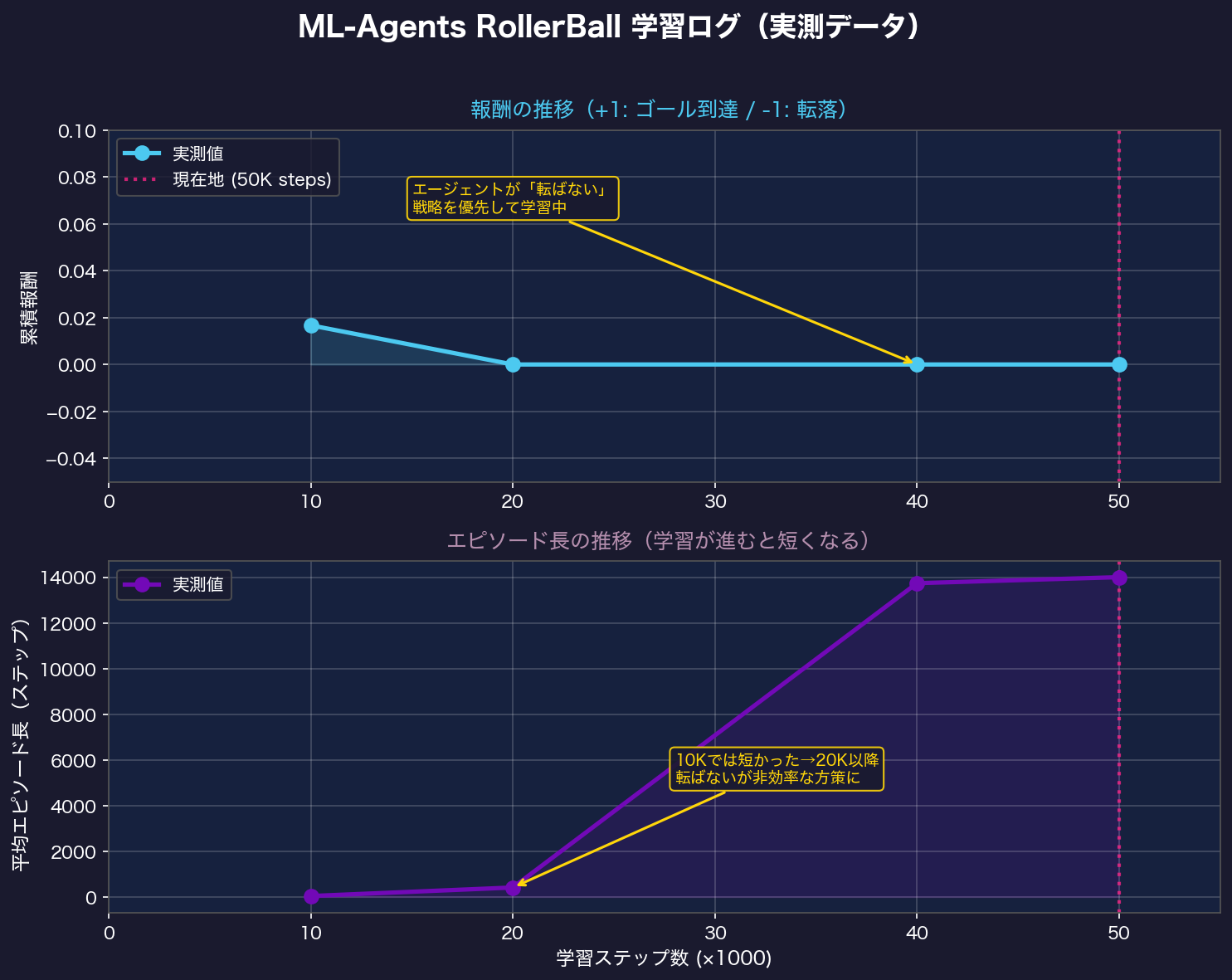
学習ログから読み取れること
TensorBoard(学習の可視化ツール)のログをtbparseライブラリで読み込んで分析した実測データです。
観察された挙動の変化
| ステップ数 | 平均報酬 | エピソード長 | エージェントの様子 |
|---|---|---|---|
| 10,000 | +0.017 | 37ステップ | すぐ転落。たまにゴール到達 |
| 20,000 | 0.0 | 411ステップ | 転落は減った。ゴールは見つけられず |
| 40,000〜50,000 | 0.0 | 13,000〜14,000ステップ | 転ばない!でも止まってる? |
「賢くなりすぎた」落とし穴
面白い現象が起きました。エピソード長が急増(37 → 14,000ステップ)していることから、エージェントは「転ばない」という負の報酬(−1)を避けることを先に学習してしまったようです。
床の端に近づかないようにゆっくり動く——これで「転落ペナルティ」は回避できます。しかし「ゴール到達ボーナス(+1)」を取りにいかないため、エピソードが終わらず長くなっています。
これは強化学習の典型的な課題のひとつ、「報酬ハッキング(Reward Hacking)」の一形態です。「悪いことをしない」ことを学んでも、「良いことをする」とは限らない。
この問題には「ステップごとに小さなペナルティを与える」設計が有効です。
例:
AddReward(-0.001f) を毎ステップ加算することで「早くゴールを目指す」動機が生まれます。
より長く学習させると…
今回は50,000ステップで途中経過を見ましたが、一般的にこのタスクでは200,000〜300,000ステップあたりで学習が収束し始めます。典型的な収束後の挙動は:
- 平均報酬が0.7〜0.9まで上昇
- エピソード長が20〜30ステップ程度まで短縮
- エージェントがほぼ一直線にターゲットへ向かう
TensorBoardで可視化する
source ~/devel/unity/ml_agents_env/bin/activate
tensorboard --logdir ~/devel/unity/MLAgents_RollerBall/results/
# ブラウザで http://localhost:6006 を開くTensorBoardを使うと、報酬の推移・Policy Loss(方策の変化量)・Value Loss(価値関数の誤差)などをリアルタイムで可視化できます。学習が順調かどうかをひと目で確認できるので必須のツールです。
NavMeshとの使い分け
以前の記事(p910: UnityのNavMeshでAIキャラに自動経路探索させてみた)でNavMeshを紹介しましたが、ML-Agentsと何が違うのでしょうか?
| 観点 | NavMesh | ML-Agents |
|---|---|---|
| 動作の仕組み | 事前に計算した最短経路を辿る | 試行錯誤で自力学習 |
| セットアップ | 数分〜数時間(ベイク) | 数時間〜数日(学習) |
| 予測可能性 | 高い(同じ状況なら同じ行動) | 低い(確率的な行動) |
| 適した場面 | RPGのNPC移動・ゲームAI | 複雑な物理・未知の環境・研究 |
| 動的な障害物 | NavMesh Obstacleで対応 | 自然に対応(観測に含めれば) |
一般的なゲーム開発ならNavMesh、物理ベースの複雑な行動や研究目的ならML-Agentsというのが現実的な使い分けです。
まとめ
Unity ML-Agentsで強化学習エージェントを育ててみた体験をまとめました。
- ✅ 環境構築:Python 3.10.12 + venv + --no-deps + --prefer-binary で依存地獄を突破
- ✅ シーン構成:Floor + Target + RollerAgent(Rigidbody + Behavior Parameters + Decision Requester)
- ✅ 学習の仕組み:観測8次元 → PPOニューラルネット → 行動2次元 → 報酬でフィードバック
- ⚠️ 落とし穴:報酬ハッキング——「転ばない」を先に学んで「ゴールを目指す」を後回しにした
- 📖 次のステップ:ステップペナルティの追加、複数エージェントの並列学習、カリキュラム学習
強化学習の「AIが自分で賢くなる」面白さを体感できただけで大満足です。完全収束した姿を見るには、もう少し学習を続ける必要がありますが、その過程——ランダムに動く → 転ばないことを学ぶ → ゴールを目指し始める——というプロセスこそが強化学習の醍醐味だと感じました。
それでは、今回はここまで。ありがとうございました😊