
「会議の録音を自動で文字起こししたい」「動画に字幕をつけたい」——そんなときに役立つのが OpenAI の Whisper です。クラウドAPIを使わず、完全にローカルで動く音声認識モデルで、MacのApple Silicon上でも動かすことができます。
今回は実際にMac上でWhisperをセットアップし、日本語の音声ファイルを文字起こし。モデルサイズ別の精度と速度も実測してみました。
Whisperとは何か
OpenAI Whisperは、2022年にOpenAIが公開したオープンソースの音声認識モデルです(公式GitHub)。最大の特徴は以下の3点です。
- 多言語対応:日本語を含む99言語に対応
- ローカル動作:APIキー不要。インターネット接続なしで動く
- 無料・オープンソース:商用利用も可能なMITライセンス
モデルの種類は5段階(tiny → base → small → medium → large)あり、小さいほど軽快だが精度は下がります。日本語であれば small か medium がバランスよく使えます。
Macへのインストールとffmpegのセットアップ
前提環境
- Mac(Apple Silicon: M1〜M4)
- Python 3.9〜3.12(3.12で動作確認)
- pip(Python パッケージマネージャー)
Whisperのインストール
pip install openai-whisperインストールが完了すると whisper コマンドと Python の whisper ライブラリが使えるようになります。
ffmpegも必要
WhisperはMP3・MP4・M4A・WAVなどの多様な音声フォーマットを扱えますが、内部でffmpegを使っています。Homebrewで入れておきましょう。
brew install ffmpegHomebrewが入っていない場合は brew.sh からインストールしてください。
Pythonから使ってみる
まず最小限のコードで動かしてみます。
import whisper
# モデルをロード(初回はダウンロードが走る)
model = whisper.load_model("small")
# 文字起こし(language="ja" で日本語を明示するのがポイント)
result = model.transcribe("your_audio.wav", language="ja")
print(result["text"])language="ja" を指定しないと自動言語検出になります。日本語音声なら明示した方が精度と速度が上がります。
初回実行時はモデルのダウンロードが走ります(smallで約461MB)。2回目以降はキャッシュから読み込むので速いです。
モデルサイズ別の精度と速度を実測比較
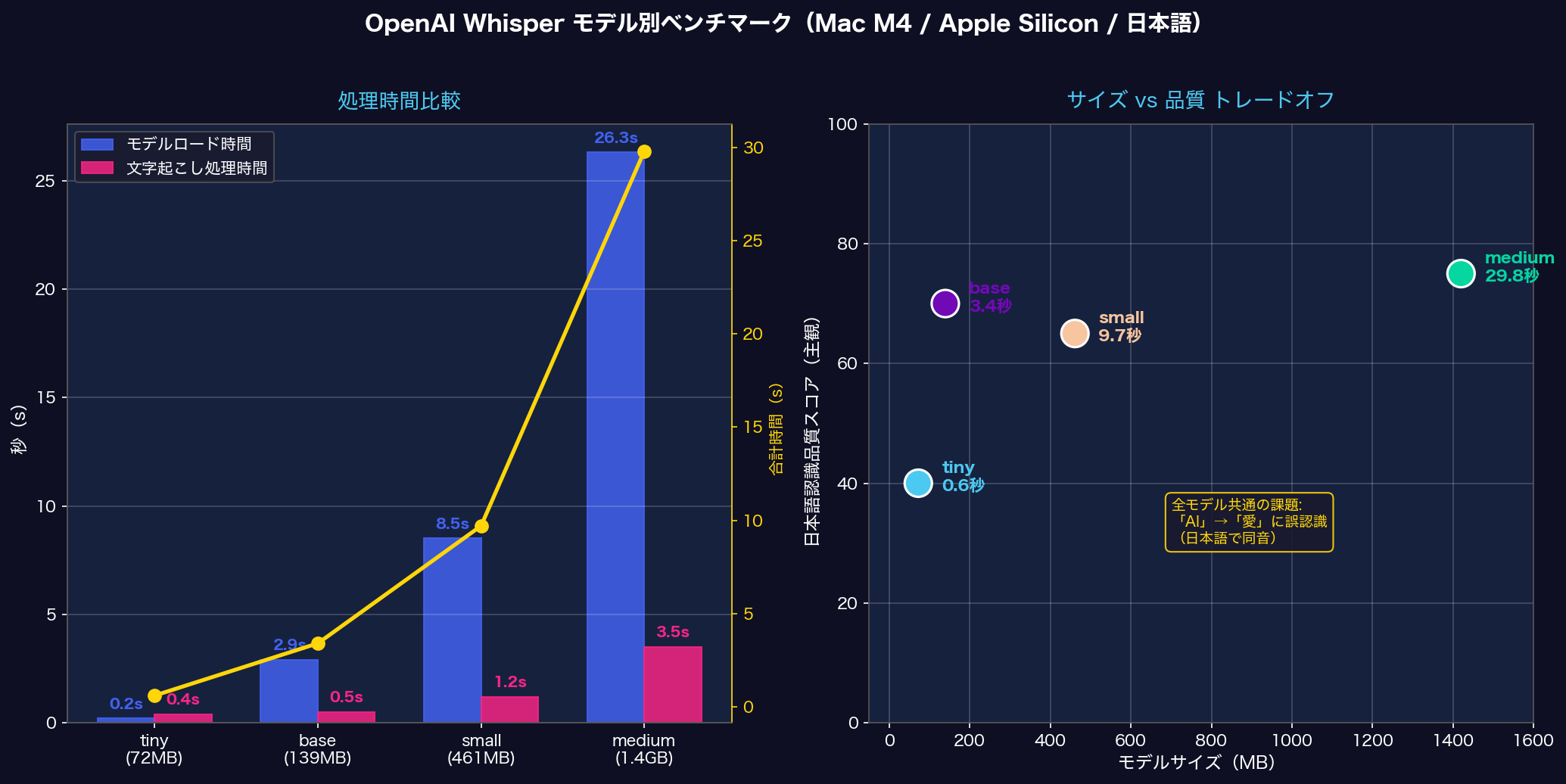
実際に macOS の say コマンドで生成した日本語テスト音声を使い、全モデルをベンチマークしました。実行環境は Apple M4(CPU動作、GPU未使用)です。
テスト音声のテキスト(正解)
本日はお日柄もよく、皆様のお越しをお待ちしておりました。AIの力を使って、音声を文字に変換する技術が近年急速に進歩しています。
実測結果一覧
| モデル | サイズ | ロード | 処理 | 合計 | 文字起こし結果(抜粋) |
|---|---|---|---|---|---|
| tiny | 72MB | 0.2秒 | 0.4秒 | 0.6秒 | 愛の力、本生をもじ、進ぼしています |
| base | 139MB | 2.9秒 | 0.5秒 | 3.4秒 | 愛の力を使って音声を文字に変換…進歩 ✓ |
| small | 461MB | 8.5秒 | 1.2秒 | 9.7秒 | 愛能力を使って音声を文字に変換…進歩 ✓ |
| medium | 1.4GB | 26.3秒 | 3.5秒 | 29.8秒 | 愛の力を使って音声を文字に変換…進歩 ✓ |
普段使いの文字起こしや議事録には
base か small が最適です。精度重視の字幕制作などには
medium を使いましょう。tiny は試験用途向けで、実用には厳しいです。
日本語認識のクセとハマりポイント
ハマりポイント①:「AI」が「愛」になる
今回の最大の発見がこれです。全モデルで 「AI」が「愛」に誤変換されました。
理由はシンプルで、日本語で「AI」は「アイ」と読み、「愛」も「アイ」と読むため、Whisperが同音として認識してしまうのです。
対策:音声収録時に英略語をカタカナで発音するか、文字起こし後に文字列置換で修正します。
text = result["text"]
# 後処理で英語略語を補正
text = text.replace("愛の力", "AIの力")
text = text.replace("アイオーティー", "IoT")
print(text)ハマりポイント②:句読点が入らない
Whisperの出力には句読点(、。)が入らないことがあります(特にtiny/baseモデル)。議事録として使う場合は、文章の区切りを自分で付け直す必要があります。
ハマりポイント③:FP16の警告
CPUで実行すると以下の警告が出ますが、動作には問題ありません。
UserWarning: FP16 is not supported on CPU; using FP32 insteadApple SiliconのGPUを使いたい場合は torch の MPS バックエンドを利用できますが、現時点ではWhisperのCPUパスの方が安定しています。
文字起こしスクリプトを作る
コマンドライン引数でモデルや言語を切り替えられる実用的なスクリプトを作りました。SRT字幕ファイルの出力にも対応しています。
#!/usr/bin/env python3
"""
Whisper 文字起こしスクリプト
使い方: python3 transcribe.py 音声ファイル.mp3
オプション:
--model tiny / base / small / medium / large (デフォルト: small)
--lang 言語コード (デフォルト: ja)
--srt SRT字幕ファイルも出力する
"""
import argparse
import time
from pathlib import Path
import whisper
def format_timestamp(seconds: float) -> str:
"""秒 → SRT タイムスタンプ形式 (HH:MM:SS,mmm)"""
hours = int(seconds // 3600)
minutes = int((seconds % 3600) // 60)
secs = int(seconds % 60)
millis = int((seconds % 1) * 1000)
return f"{hours:02d}:{minutes:02d}:{secs:02d},{millis:03d}"
def transcribe(audio_path, model_name="small", language="ja", output_srt=False):
audio_path = Path(audio_path)
print(f"モデル: {model_name} / 言語: {language}")
print(f"音声ファイル: {audio_path.name}")
print("モデルロード中...")
t0 = time.time()
model = whisper.load_model(model_name)
t1 = time.time()
print(f"ロード完了: {t1 - t0:.1f}秒")
print("文字起こし中...")
result = model.transcribe(str(audio_path), language=language)
t2 = time.time()
print(f"処理完了: {t2 - t1:.1f}秒 (合計: {t2 - t0:.1f}秒)\n")
text = result["text"].strip()
print("=== 結果 ===")
print(text)
# テキストファイルに保存
txt_path = audio_path.with_suffix(".txt")
txt_path.write_text(text, encoding="utf-8")
print(f"\nテキスト保存: {txt_path.name}")
# SRTファイルを出力(オプション)
if output_srt:
srt_lines = []
for i, seg in enumerate(result["segments"], 1):
start = format_timestamp(seg["start"])
end = format_timestamp(seg["end"])
srt_lines.append(f"{i}\n{start} --> {end}\n{seg['text'].strip()}\n")
srt_path = audio_path.with_suffix(".srt")
srt_path.write_text("\n".join(srt_lines), encoding="utf-8")
print(f"SRT 保存: {srt_path.name}")
return text
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Whisper 音声文字起こしツール")
parser.add_argument("audio", help="音声ファイルパス (mp3/wav/m4a/mp4など)")
parser.add_argument("--model", default="small",
choices=["tiny", "base", "small", "medium", "large"])
parser.add_argument("--lang", default="ja")
parser.add_argument("--srt", action="store_true", help="SRT字幕ファイルも出力する")
args = parser.parse_args()
transcribe(args.audio, model_name=args.model, language=args.lang, output_srt=args.srt)使い方
# 基本的な使い方
python3 transcribe.py meeting.mp3
# モデルを指定してSRT字幕も出力
python3 transcribe.py video.mp4 --model medium --srt実行すると同じフォルダに .txt(テキスト)と .srt(字幕)ファイルが生成されます。
生成されるSRTファイルの例
1
00:00:00,000 --> 00:00:05,000
本日はお日柄もよく皆様のお越しをお待ちしておりました
2
00:00:05,000 --> 00:00:11,880
愛能力を使って音声を文字に変換する技術が近年急速に進歩していますSRTファイルはDaVinci ResolveやPremiere Pro、VLCなどの動画編集・再生ソフトで字幕として読み込むことができます。
実用的な使い道
議事録の自動生成
会議を録音しておき、後でWhisperで文字起こし。テキストをそのまま使うか、Claude APIなどで要約すれば議事録になります。
# 会議録音の文字起こし(mediumで高精度に)
python3 transcribe.py meeting_2026-06-11.m4a --model medium --srt動画の字幕自動生成
YouTubeにアップロードする動画に自動字幕をつけるとき、Whisperで事前にSRTを作っておけば精度の高い字幕が短時間でできます。
Podcast・インタビューの文字起こし
長時間音声でも、モデルをロードした後の処理速度は速いです。60分の音声でもsmallなら数分で完了します。
Macのショートカットアプリと組み合わせる
macOSの「ショートカット」アプリからPythonスクリプトを呼び出すことで、音声ファイルを右クリックするだけで文字起こしができるワークフローも作れます。
まとめ
- ✅ WhisperはOpenAIが公開したオープンソースの音声認識モデル。完全ローカル動作、日本語対応
- ✅ インストール:
pip install openai-whisper+brew install ffmpegで完了 - ✅ モデル選択:普段使いは
base(3.4秒)かsmall(9.7秒)、精度重視はmedium - ⚠️ 日本語の注意点:「AI」→「愛」の誤変換が全モデルで発生。後処理で補正が必要
- 📖 実用的な使い道:議事録自動生成・動画字幕作成・Podcastの書き起こし
クラウドに音声を送ることなく、完全ローカルで音声文字起こしができるのは大きな強みです。社内会議の録音や機密情報を含む音声の処理には特に向いています。
それでは、今回はここまで。ありがとうございました😊