
RAGってそもそも何?
最近「RAG」という言葉をよく耳にするようになりました。ChatGPTやClaudeといったAIツールを使っていると、「社内ドキュメントを読み込んだAI」や「自分のメモを元に答えてくれるチャットボット」の話が出てきます。その多くが RAG という仕組みを使っています。
RAG とは Retrieval-Augmented Generation(検索拡張生成)の略です。日本語にすると「情報を検索してから文章を生成する」という意味で、LLM(大規模言語モデル)が知らない情報を外部から補ってあげる仕組みです。
一言でいえば、「AIの脳みそ(LLM)」と「自分の本棚(ナレッジベース)」を合体させる技術です。
LLMだけでは何が足りないのか
ChatGPTやClaudeは非常に賢いですが、いくつかの根本的な制限があります。
| 限界 | 具体例 |
|---|---|
| 学習データに含まれない情報は知らない | 自社のマニュアル・社内規定・個人メモなど |
| 学習カットオフ以降の情報は知らない | 最新ニュース・最近リリースされたライブラリなど |
| 「もっともらしい嘘」をつく(ハルシネーション) | 存在しないURLや書籍を自信を持って答える |
RAG はこれらの問題を「正しい情報を先に引っ張ってきて、それをもとに回答させる」という方法で解消します。人間でいえば、試験会場に参考書を持ち込んで答える「持ち込みOK方式」のようなものです😊
RAGの仕組みをざっくり理解する
RAG には大きく2つのフェーズがあります。
フェーズ①:事前準備(Indexing)
ドキュメント(テキスト)をベクトル化して保存します。ベクトル化とは、文章の意味を数値の配列(ベクトル)に変換することです。意味が似ている文章ほど近い数値になります。
フェーズ②:検索&生成(Retrieval + Generation)
ユーザーの質問をベクトル化し、事前に保存したドキュメントと照合して「一番意味が近いもの」を取り出します。その取り出した文章を LLM に渡し、「この情報を使って回答して」と指示することで、正確な回答を生成させます。
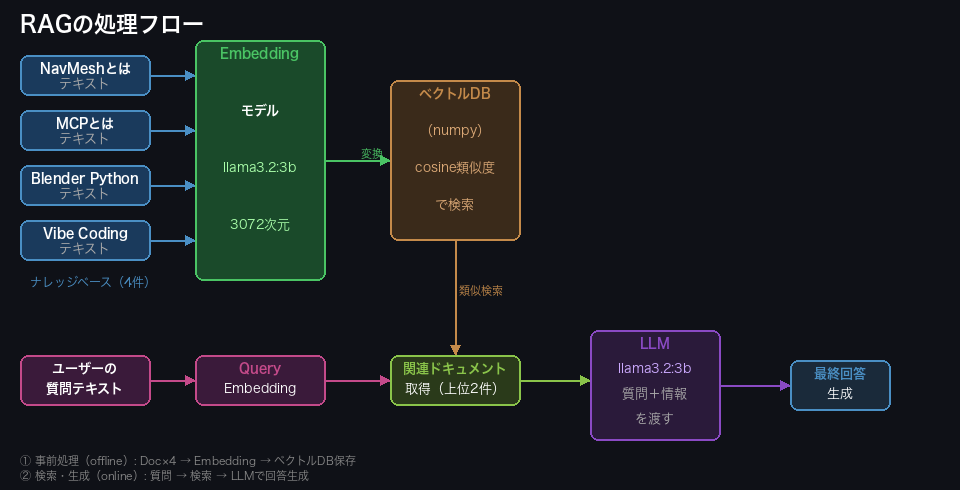
ベクトル同士の類似度を測る方法として コサイン類似度 がよく使われます。2つのベクトルが向いている方向が近いほど「意味が似ている」と判断します。値は -1 〜 1 で、1 に近いほど類似しています。
OllamaのローカルLLMでRAGを実装してみた
理屈がわかったところで、実際に手元の Mac で動かしてみました。外部 API は一切使わず、ローカルで動く LLM(Ollama)だけで完結させています。
使用した環境
| 項目 | 内容 |
|---|---|
| LLM | llama3.2:3b(Meta製、3B パラメータ、2.0GB) |
| 実行環境 | Ollama(Mac ローカル) |
| Embedding | Ollama の /api/embed(llama3.2:3b で 3072 次元) |
| ベクトルDB | numpy だけで自作(外部ライブラリ不要) |
| Python パッケージ | requests、numpy のみ |
Ollama は以前 Mac に導入済みの環境を使っています(Ollama 公式サイト)。ollama run llama3.2:3b でモデルをダウンロードするだけで、API サーバーが localhost:11434 で起動します。
コードの全体像
外部のベクトル DB(Chroma や FAISS など)は使わず、numpy のコサイン類似度だけで検索を実装しました。これが最小構成の RAG です。
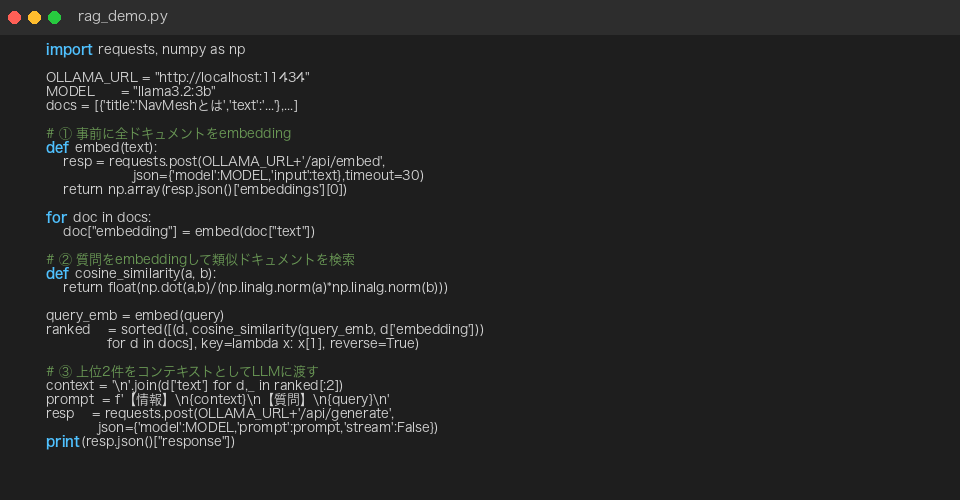
import requests
import numpy as np
OLLAMA_URL = "http://localhost:11434"
MODEL = "llama3.2:3b"
# ナレッジベース(自前のドキュメント)
docs = [
{"title": "NavMeshとは", "text": "NavMeshはUnityのAI経路探索..."},
{"title": "MCPとは", "text": "MCPはAnthropicの通信規格..."},
# ...
]
# ① 事前に全ドキュメントをembedding
def embed(text):
"""Ollama embedding API でテキストをベクトル化(3072次元)"""
resp = requests.post(OLLAMA_URL + "/api/embed",
json={"model": MODEL, "input": text}, timeout=30)
return np.array(resp.json()["embeddings"][0])
for doc in docs:
doc["embedding"] = embed(doc["text"])
# ② 質問をembeddingして類似ドキュメントを検索
def cosine_similarity(a, b):
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
query_emb = embed(query)
ranked = sorted(
[(d, cosine_similarity(query_emb, d["embedding"])) for d in docs],
key=lambda x: x[1], reverse=True
)
# ③ 上位2件をコンテキストとしてLLMに渡す
context = "\n".join(d["text"] for d, _ in ranked[:2])
prompt = f"【情報】\n{context}\n【質問】\n{query}\n"
resp = requests.post(OLLAMA_URL + "/api/generate",
json={"model": MODEL, "prompt": prompt, "stream": False})
print(resp.json()["response"])コードのポイントは3ステップだけです。①ドキュメントをベクトル化→②質問と類似したものを取り出す→③LLMに渡して回答させる。この流れがRAGのすべてです。
実行結果
実際に2つの質問で試してみました。
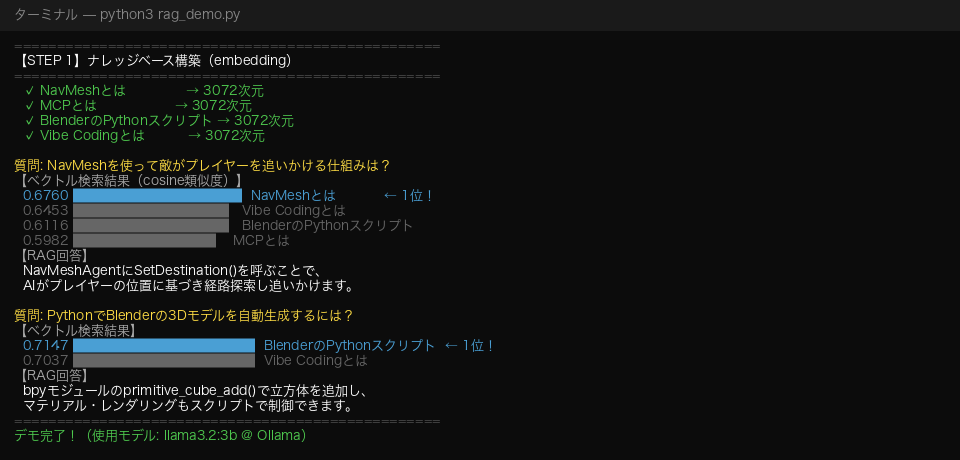
「NavMeshを使って敵がプレイヤーを追いかける仕組みは?」という質問に対して、NavMesh のドキュメントが類似度 0.6760 で1位になり、正しく回答が生成されました。
「PythonでBlenderの3Dモデルを自動生成するには?」という質問では、Blender のドキュメントが 0.7147 で1位になり、bpy モジュールの説明を正確に使って回答してくれました。
ナレッジベースに存在しない情報については「情報がありません」と正直に答えてくれるのも大きなポイントです。プロンプトで「情報に書かれていないことは答えないでください」と指示することで、ハルシネーションを抑制できます。
RAGを使うときの注意点
RAGは便利ですが、いくつか注意点もあります。
① 検索で取れなかったら回答も悪くなる
RAG の品質はベクトル検索の精度に依存します。質問の言い回しとドキュメントの表現が大きくずれると、関係のないドキュメントが上位に来てしまいます。今回の実験でも、「UnityでAIを使って敵を動かすには?」という少し遠回りな質問では NavMesh が1位にならないケースがありました。質問の言い回しを工夫するか、ドキュメントを細かく分割(チャンキング)することが対策になります。
② ドキュメントが多いほど重くなる
今回は4件だけでしたが、ドキュメントが数百件になると embedding の事前計算とメモリ使用量が増えます。本格的に使うなら Chroma や FAISS などの専用ベクトル DB を使うのがおすすめです。
③ embedding モデルの品質が重要
llama3.2:3b の embedding は 3072 次元と十分な精度ですが、日本語テキストの場合は日本語に特化した embedding モデル(例:multilingual-e5 など)を使うとさらに精度が上がります。
まとめ
RAG を一言でまとめると、「LLMの脳みそに、自分の本棚の情報を追加して使う仕組み」です。今回のポイントをまとめます。
- LLM は学習データ外の知識を持たない → RAG で補える
- ドキュメントをベクトル化(embedding)して保存するのが事前準備
- 質問をベクトル化してコサイン類似度で検索するのが Retrieval
- 取り出した情報をプロンプトに入れて回答させるのが Generation
- Ollama + numpy だけで最小構成の RAG を実装できる
今回作ったコードはほんの50行ほどです。「社内マニュアルを読み込んだAI」や「自分のメモを参照してくれるアシスタント」を作りたい方は、ぜひ試してみてください😊
それでは、今回はここまで。ありがとうございました😊