以前の記事(p914: Stable DiffusionをMacで動かしてみた)では、AUTOMATIC1111のWebUIでAI画像生成を試しました。今回はもう一歩進んで、ComfyUIというノードベースのツールで画像生成ワークフローを自分で組んでみます。
MacのApple Silicon(M4)上で実際にインストールから画像生成まで行い、つまずいたポイントも紹介します。
ComfyUIとは何か(WebUIとの違い)
ComfyUIは、Stable Diffusionを「ノード(箱)」と「線」で操作する画像生成ツールです(公式GitHub)。
WebUIがフォームに入力する家電のような操作感だとすると、ComfyUIは処理の流れを自分で配線するイメージです。「モデルを読み込む」「プロンプトを変換する」「ノイズを除去する」といった各工程がノードになっていて、それらを線で繋いで1つのワークフローを作ります。

最初はとっつきにくいですが、処理の流れが目で見えること、同じ設定を丸ごと保存・共有できることが大きな魅力です。
Macへのインストール手順
前提環境
- Mac(Apple Silicon: M1〜M4)
- Python 3.12 / PyTorch 2.x(MPS対応版)
- git
- 空きディスク容量 約6GB以上(モデル4GB+本体)
1. ComfyUI本体を取得
cd ~
git clone --depth 1 https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI2. 依存ライブラリをインストール
pip install -r requirements.txtPyTorchが未導入の場合は先に入れておきます。Apple SiliconならMPS(Metal Performance Shaders)が自動で使われます。
# MPSが使えるか確認
import torch
print(torch.backends.mps.is_available()) # True ならOK3. モデル(チェックポイント)を配置
ComfyUIは単一ファイルのチェックポイント(.safetensors)を使います。SD1.5の標準モデルを models/checkpoints/ に置きます。
cd models/checkpoints
curl -L -o v1-5-pruned-emaonly.safetensors \
"https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors"WebUIで使っていたHuggingFace形式(text_encoder / unet / vae に分かれたフォルダ)は、ComfyUIではそのまま読み込めません。単一の .safetensors チェックポイントを別途ダウンロードして
models/checkpoints/ に置く必要があります。
起動して画面を見てみる
本体フォルダで以下を実行します。Apple Siliconでは --force-fp16 を付けると省メモリで安定します。
python3 main.py --force-fp16起動すると http://127.0.0.1:8188 でアクセスできます。ブラウザで開くと、まずテンプレート選択画面が出ます。
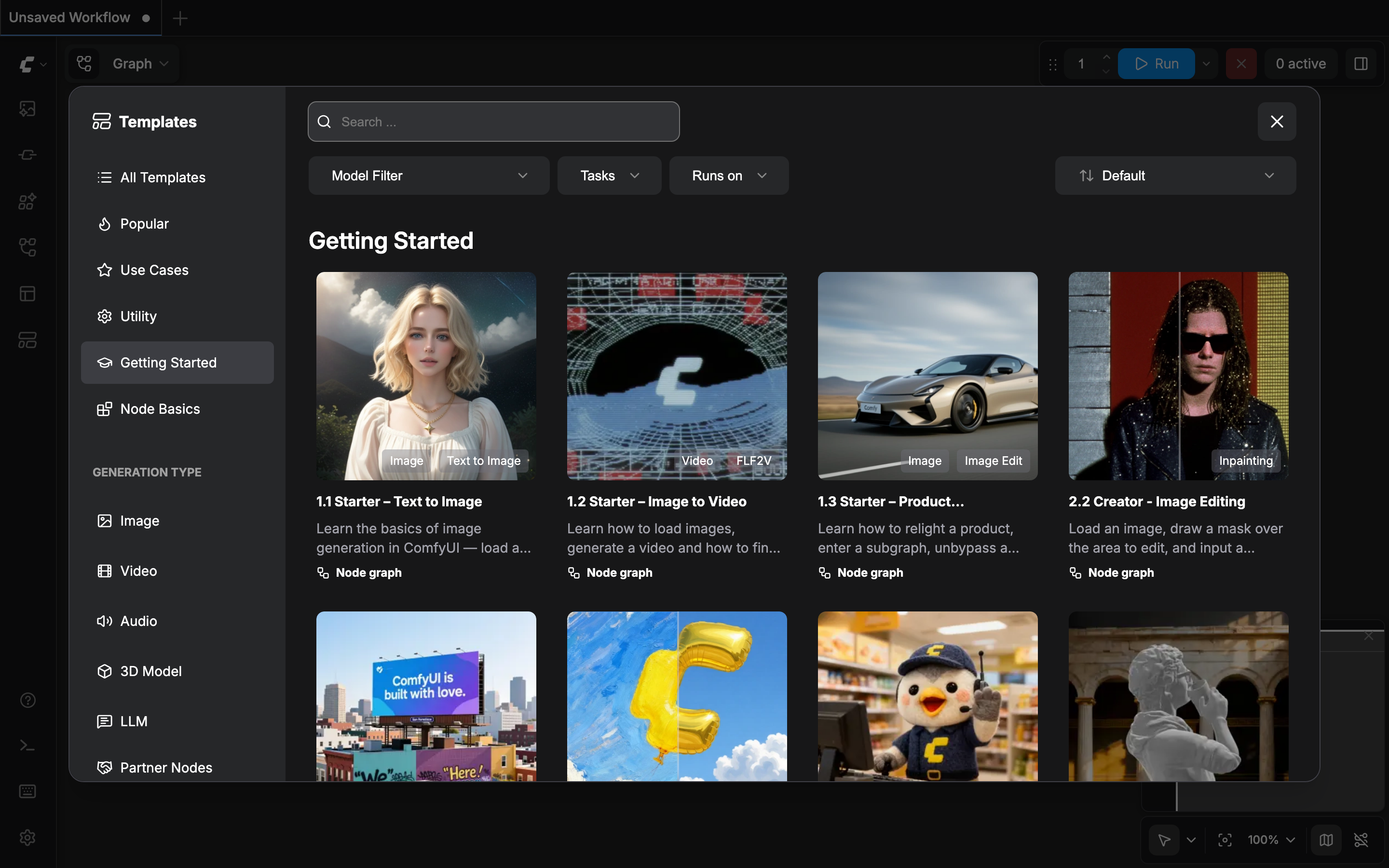
「Getting Started」の中から 1.1 Starter - Text to Image を選ぶと、基本的なワークフローが読み込まれます。
基本ワークフロー(テキスト→画像)を組む
これが実際のComfyUIの画面です。各ノードが線で繋がっているのが分かります。
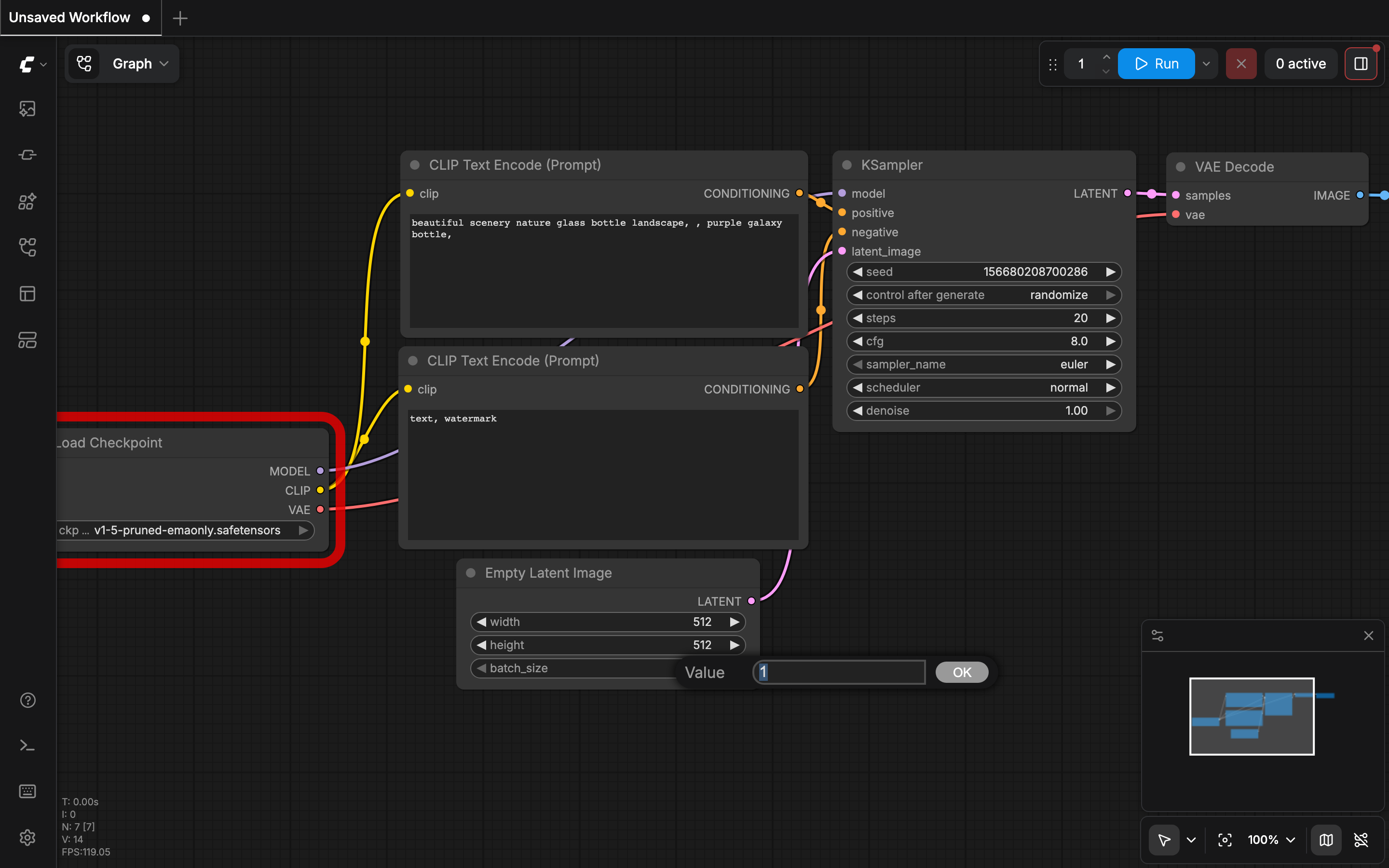
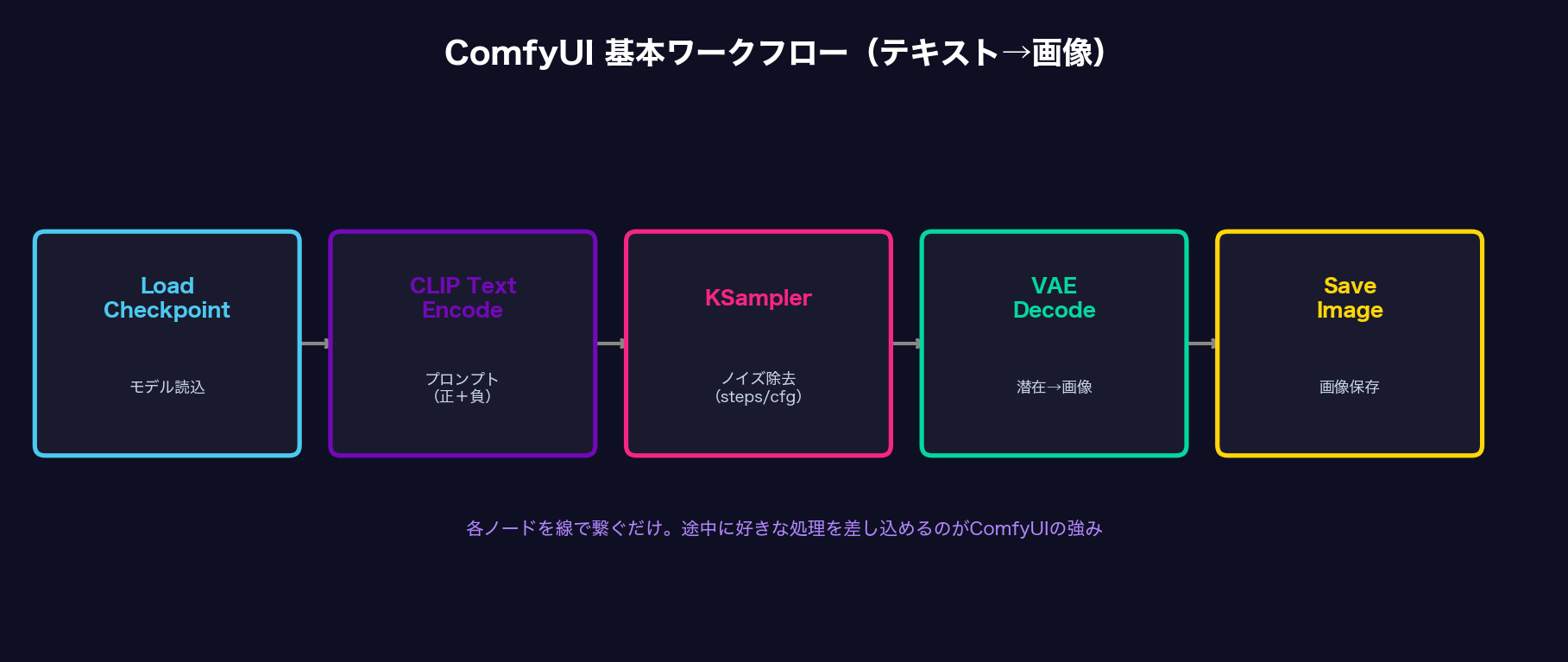
テキスト→画像の基本ワークフローは、以下の5つのノードで構成されています。
| ノード | 役割 |
|---|---|
| Load Checkpoint | モデル(.safetensors)を読み込む |
| CLIP Text Encode | プロンプト(正・負の2つ)を数値に変換 |
| Empty Latent Image | 生成する画像サイズ(512×512など)を指定 |
| KSampler | ノイズを除去して画像を生成(steps / cfg / seed) |
| VAE Decode → Save Image | 潜在表現を画像に変換して保存 |
右上の Run ボタンを押すと、配線したワークフローが順に実行されて画像が生成されます。
実際に画像を生成してみた
SD1.5モデルで、いくつかのプロンプトを試しました。1枚あたり 約19秒(Apple M4 / 512×512 / 20ステップ)で生成できました。



左から「桜と山と川の風景」「窓辺の猫」「サイバーパンクな夜の街」です。プロンプトと seed を変えるだけで全く違う画像が出てきます。
使ったプロンプトの例(風景):
Positive: a beautiful japanese mountain landscape, cherry blossoms,
river, masterpiece, highly detailed, 8k
Negative: low quality, blurry, distorted, watermark, text, ugly, bad anatomyimg2imgで画像を作り変える
ComfyUIの真価は、ワークフローを差し替えるだけで別の処理ができる点です。先ほどの「桜の風景」を入力にして、img2img(画像→画像)で冬の雪景色に作り変えてみました。

左が元画像(桜)、右がimg2imgの結果(雪山+寒色系)です。構図は保ったまま、雰囲気だけを変えることができました。
img2imgでは、基本ワークフローに Load Image と VAE Encode のノードを追加し、KSamplerの denoise を下げます(今回は0.6)。
| denoiseの値 | 効果 |
|---|---|
| 0.3〜0.5 | 元画像をほぼ保持。軽い加工・補正向き |
| 0.6〜0.7 | 構図は残しつつ雰囲気を大きく変える(今回) |
| 0.8〜1.0 | ほぼ別画像。元画像は構図のヒント程度 |
ControlNetなど応用ワークフロー
ComfyUIには、さらに高度なワークフローを組むための拡張があります。代表的なのが ControlNet です。
- ControlNet:線画・ポーズ・深度などで「構図を指定」して生成する。人物のポーズを固定したまま絵柄だけ変える、といったことが可能
- Upscale(高解像度化):生成した画像をワークフロー内で2倍・4倍に拡大
- LoRA:特定の画風やキャラクターを追加学習したモデルを差し込む
- Inpaint(部分修正):画像の一部だけをマスクして描き直す
これらは ControlNet Loader や Upscale といった専用ノードを既存のワークフローに繋ぐだけで追加できます。ControlNetを使う場合は対応モデル(約1.4GB)の追加ダウンロードが必要です。
ComfyUIで生成した画像のPNGには、ワークフロー情報が埋め込まれています。その画像をComfyUIにドラッグ&ドロップするだけで、同じノード構成が丸ごと復元されます。配布されているワークフローを試すのも簡単です。
WebUIとの使い分け
p914で使ったWebUIと、今回のComfyUI。どちらを使うべきか、実際に両方触った感想をまとめます。
- WebUIが向いている人:とにかく手軽に画像を作りたい。プロンプトを変えて量産したい。AI画像生成が初めて
- ComfyUIが向いている人:img2img・ControlNet・Upscaleを組み合わせた複雑な処理をしたい。同じ手順を何度も再現したい。処理の中身を理解したい
個人的には、まずWebUIで感覚を掴んでから、こだわり始めたらComfyUIに移行するのが良い流れだと感じました。ComfyUIは最初こそ複雑に見えますが、一度ワークフローの仕組みが分かると「あの処理をここに挟みたい」が自由にできて、表現の幅が一気に広がります。
まとめ
- ✅ ComfyUIはノードと線で画像生成を組み立てるツール。処理の流れが見える
- ✅ インストール:git clone →
pip install -r requirements.txt→ チェックポイントをmodels/checkpoints/に配置 - ✅ 基本ワークフロー:Load Checkpoint → CLIP Text Encode → KSampler → VAE Decode → Save Image
- ✅ 生成速度:Apple M4で512×512・20ステップが約19秒
- ⚠️ ハマりポイント:WebUIのHuggingFace形式モデルは使えず、単一.safetensorsが必要
- 🎨 応用:img2img・ControlNet・Upscale・LoRAをノードで自由に組み合わせられる
WebUIの手軽さも魅力ですが、ComfyUIで「自分だけのワークフロー」を組む楽しさは格別でした。AI画像生成を本格的に使いこなしたい方には、ぜひ一度触ってみてほしいツールです。
それでは、今回はここまで。ありがとうございました😊