
Stable Diffusionとは何か
「Stable Diffusion」は、テキスト(プロンプト)を入力するだけで画像を生成できるAIモデルです。2022年にStability AI社がオープンソースで公開し、誰でも無料で使えることから爆発的に普及しました。
仕組みをざっくり説明すると、「ランダムなノイズから少しずつノイズを除去していく」という拡散モデル(Diffusion Model)を使っています。最初は砂嵐のような画像から始まり、20〜50ステップかけて徐々にプロンプト通りの画像に「引き寄せられて」いくイメージです。
GPU(グラフィックカード)を使うことが多いですが、Apple Silicon(M1〜M4チップ)には MPS(Metal Performance Shaders) という独自のGPUアクセラレーション機能があり、これを使えばMacのみで十分な速度で動作します。
MacでStable Diffusionを動かす方法の選択肢
Macで動かす方法はいくつかあります。今回は全て試しながら最適解を探しました。
| 方法 | 特徴 | 難易度 |
|---|---|---|
| AUTOMATIC1111 (Stable Diffusion WebUI) |
最も有名なWebUIツール。ブラウザで操作できる。ただし最新macOS・Python環境では依存パッケージのビルドエラーが発生しやすい | ⭐⭐⭐(環境依存あり) |
| Hugging Face diffusers | PythonライブラリでAPIレベルから使う方法。pip install diffusersだけで動く。今回採用 |
⭐⭐(中程度) |
| Draw Things | Mac App Store配布のネイティブアプリ。インストール最簡単。設定の自由度は低め | ⭐(簡単) |
| ComfyUI | ノードを繋いでワークフローを組む上級者向けUI。柔軟性が高い | ⭐⭐⭐(上級者向け) |
今回は Hugging Face diffusers を使います。依存パッケージが少なく、Pythonさえあれば動くので最もトラブルが少ないためです。また「中で何が起きているか」が見えやすく、エンジニアとして理解しやすい点も気に入っています。
セットアップ手順(全ステップ解説)
① Python環境の準備
まず pyenv で Python 3.12 系を使います。ただし、注意点があります。pyenv でビルドした Python は、依存ライブラリ(xz など)が不足していると後でエラーになることがあります。以下の手順で確実にセットアップしてください。
# xz(lzmaモジュールに必要)を先にインストール
brew install xz
# Pythonビルド時にxzをリンクするよう指定してインストール
LDFLAGS="-L/opt/homebrew/opt/xz/lib" \
CPPFLAGS="-I/opt/homebrew/opt/xz/include" \
pyenv install 3.12.5⚠️ ハマりポイント①:xz を Homebrew でインストール済みでも、Python をビルドする前に環境変数を設定しないとリンクされません。後から python3 -c "import lzma" でエラーが出たら、上記の手順で Python を再ビルドしてください。
② PyTorch(MPS対応版)のインストール
pip install torch torchvisionApple Silicon 向けの PyTorch は pip install だけで MPS サポート付きでインストールされます。インストール後に動作確認しましょう。
python3 -c "
import torch
print('PyTorch version:', torch.__version__)
print('MPS available:', torch.backends.mps.is_available())
"MPS available: True と表示されれば成功です。Apple M4 で確認した結果、PyTorch 2.12.0 / MPS = True でした。
③ diffusersとツール類のインストール
pip install diffusers transformers accelerate safetensorsこれだけです。4つ合わせて数分でインストール完了します。
最初の画像を生成してみる
セットアップが完了したら、以下のスクリプトで最初の画像を生成できます。
import os, torch
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1" # MPS非対応の演算をCPUにフォールバック
from diffusers import StableDiffusionPipeline
# モデルをダウンロード(初回のみ約4.3GB)
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float32, # MPSではfloat32が安定
safety_checker=None,
)
pipe = pipe.to("mps")
pipe.enable_attention_slicing() # メモリ節約
# 画像を生成
image = pipe(
"a beautiful sunset over mountains, photorealistic, golden hour, 4k",
num_inference_steps=20,
guidance_scale=7.5,
generator=torch.Generator("mps").manual_seed(42)
).images[0]
image.save("output.png")初回実行時はモデルのダウンロード(約4.3GB)が走ります。2回目からはキャッシュを使うので数秒でロード完了します。
実際に生成した画像がこちらです。



ハマったポイントと対処法
実際に動かすまでにいくつかハマりました。同じところで詰まる方のために対処法をまとめます。
① xz/lzmaエラー(ModuleNotFoundError: No module named '_lzma')
pyenv でビルドした Python に xz がリンクされていないと発生します。前述の通り、brew install xz の後に LDFLAGS/CPPFLAGS を指定して Python を再ビルドすれば解消します。
② 黒画像(真っ黒の512×512が出力される)
これが一番ハマりました。torch_dtype=torch.float16 を使うと、MPS上でVAE(画像デコーダ)がNaN(計算不能値)を出力して黒画像になることがあります。
対策は2つです:
- 【推奨】
torch.float32を使う。速度は少し落ちますが確実に動きます PYTORCH_ENABLE_MPS_FALLBACK=1を設定しつつtorch.float16を試す(機種によっては動く)
AUTOMATIC1111 の macOS 用スクリプト(webui-macos-env.sh)でも --no-half-vae オプションで同じ問題を回避しています。
③ AUTOMATIC1111のインストールで詰まった
今回 AUTOMATIC1111 も試しましたが、Python 3.11 + pip の最新版の組み合わせで CLIP パッケージのビルド時に pkg_resources が見つからないエラーが出ました。setuptools のバージョンを 67.8.0 に固定することで回避できましたが、このあたりの依存関係は環境によって変わります。Python のバージョン依存の問題が頻繁に起きるため、diffusers での実行の方がシンプルです。
ステップ数と生成時間・品質の比較
ステップ数を変えて同じプロンプトで生成した結果を比較しました。使用環境は Apple M4 / PyTorch 2.12.0 / float32 です。
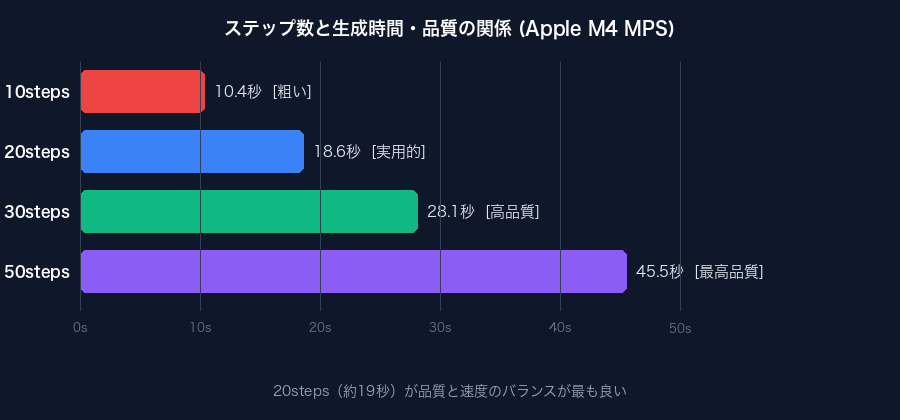
| ステップ数 | 生成時間 | 品質感 | おすすめ用途 |
|---|---|---|---|
| 10steps | 約14秒 | 粗い・ぼやけ気味 | プロンプト確認など素早いテスト |
| 20steps | 約26秒 | 実用的な品質 ★推奨 | 日常使いのバランス設定 |
| 30steps | 約38秒 | 高品質・細部が整う | SNS投稿・ブログ掲載など |
| 50steps | 約60秒 | 最高品質・改善は微細 | 印刷・拡大表示など |
実際に4つを見比べると、10steps では輪郭がぼやけていますが、20steps からは実用的な品質になります。30→50 の差は微妙で、時間をかけるわりに見た目の変化は小さいです。20stepsがコスパ最良だと感じました。
各ステップで実際に生成した画像を並べて確認してみてください。




プロンプトの書き方
Stable Diffusion はプロンプトの書き方で結果が大きく変わります。基本的な構造を押さえておきましょう。

よく使うスタイルキーワード
| カテゴリ | キーワード例 |
|---|---|
| 写真風 | photorealistic, photography, DSLR, sharp focus |
| イラスト・アニメ | anime style, digital art, illustration, manga |
| 絵画風 | oil painting, watercolor, impressionism, studio ghibli style |
| 品質向上 | highly detailed, masterpiece, best quality, 4k, 8k |
| 照明・雰囲気 | golden hour, cinematic lighting, dramatic shadows, neon lights |
ネガティブプロンプトの効果
ネガティブプロンプトとは「生成してほしくない要素」を指定するものです。negative_prompt パラメータで渡します。
image = pipe(
"portrait of a person, oil painting",
negative_prompt="ugly, blurry, low quality, bad anatomy, extra limbs, watermark",
num_inference_steps=20,
).images[0]同じシード値・同じプロンプトで、ネガティブプロンプトの有無を比較しました。


ネガティブプロンプトを入れると全体的に整った印象になります。生成時間はほぼ変わらないので、常に入れておくのがおすすめです。よく使うネガティブプロンプトをまとめておくと便利です。
# 汎用ネガティブプロンプト(コピペ用)
BASE_NEGATIVE = (
"ugly, blurry, low quality, bad anatomy, "
"extra limbs, deformed, watermark, text, signature"
)CFG Scale(忠実度)の調整
guidance_scale(CFG Scale)は「プロンプトにどれだけ忠実に生成するか」を制御するパラメータです。

同じプロンプト・同じシードで CFG Scale を変えて比較しました。



CFG=3.0 は自由で創造的ですがプロンプトから外れやすく、CFG=12.0 はプロンプト通りでも不自然さが出ることがあります。デフォルトの7.5が最もバランスよく、まずここから始めるのが無難です。
著作権・倫理面について
Stable Diffusion を使う上で知っておきたいことがいくつかあります。
モデルのライセンス
今回使用した SD 1.5 は CreativeML Open RAIL-M ライセンスで公開されています。商用利用は可能ですが、有害なコンテンツの生成や、人物を偽って作成したコンテンツの無断公開などは禁止されています。
生成画像の権利
AI が生成した画像の著作権については各国で議論が続いています。日本では現時点では「AIが生成した画像には著作権が発生しない」という見解が一般的です。ただし、他者の著作物に似た画像を意図的に生成・公開することはリスクを伴います。
悪用の禁止
実在する人物の画像を無断で学習させたり、フェイク画像を作って拡散するといった行為は法的・倫理的に問題になります。安全フィルター(safety_checker)を無効にして不適切なコンテンツを生成することも同様です。あくまで個人の創作やプロトタイピングの用途で楽しく使いましょう。
まとめ
今回 Apple M4 Mac 上で Stable Diffusion 1.5 を実際に動かして検証しました。結果をまとめます。
| 項目 | 結果 |
|---|---|
| セットアップ | pip install 3行だけ。ただし Python のビルド設定に要注意 |
| 生成速度(M4 MPS) | 20steps で約26秒。実用的な速度 |
| ハマりポイント | ① lzmaエラー(xzのビルドリンク忘れ)② float16での黒画像(→float32で解決) |
| おすすめ設定 | steps=20, CFG=7.5, float32, PYTORCH_ENABLE_MPS_FALLBACK=1 |
クラウドもGPUサーバーも不要で、手元の Mac だけで本格的な AI 画像生成ができます。プロンプトを変えるだけで風景・キャラクター・アート作品など様々な画像を作れるのは純粋に楽しいです😊 ぜひ試してみてください。
なお、今回使ったのは SD 1.5 ですが、より高精細な Stable Diffusion XL(SDXL) や、ノードを組み合わせてワークフローを作れる ComfyUI もあります。次回はそちらも試してみたいと思います。
それでは、今回はここまで。ありがとうございました😊